
在RAG技术中,检索与召回是关键环节。本文深入剖析了检索的多重机制,包括关键词、向量、知识图谱检索,并探讨了影响RAG系统性能的核心工程指标,助力企业级检索架构的优化。

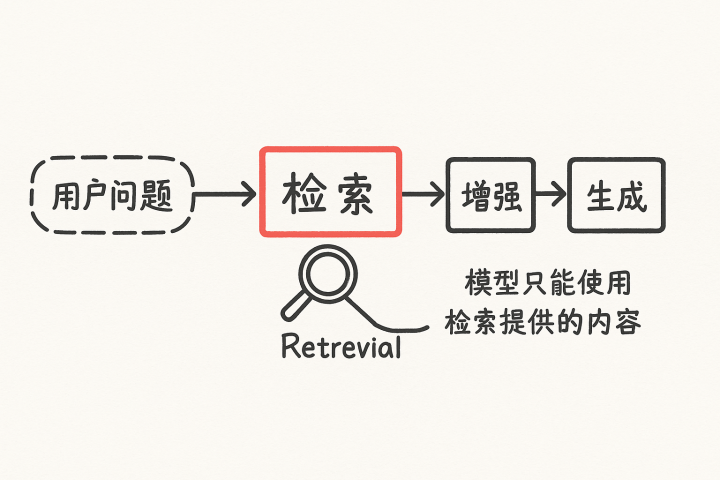
在上一期中,我们拆解了知识库构建的底层逻辑。本篇将进入RAG中最关键、最影响最终结果、也最容易被低估的部分:检索(Retrieval)与召回(Recall)。
在RAG中,模型不是在回答你的问题,而是在回答它所“看到的内容“,而这些“可见内容”完全由检索阶段决定。因此:
检索错→模型必错
检索不全→模型回答不完整
检索太多→噪声淹没关键信息
检索太慢→系统不可用
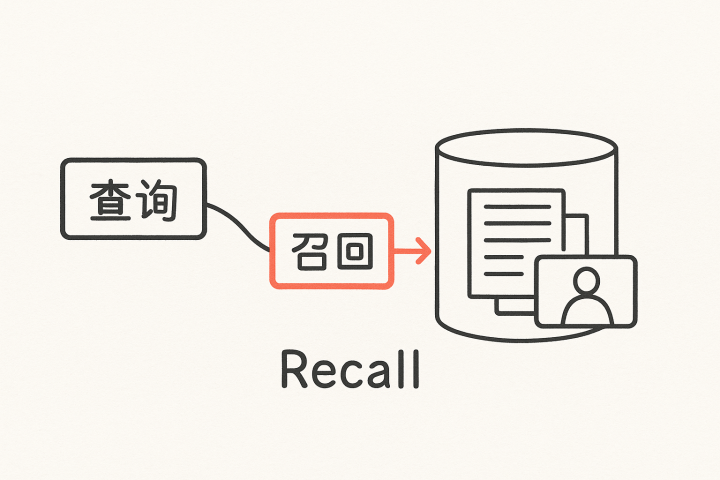
检索不是一个动作,而是一整套召回体系(RecallSystem)。
一、检索不是一个动作,而是“候选内容召回体系”
很多人理解的检索是“向量搜一下”“BM25匹配一下”,但真实情况远比这复杂。在RAG中,检索系统需要同时满足:
找到应该找的(召回率Recall)、
排除不该找的(准确率Precision)、
控制返回数量(Top-K)、
保证延迟足够低(Latency)、
保证chunk切分合理(ChunkStrategy)、
兼容不同检索方式(Sparse/Dense/Graph)
检索真正的目标不是找到答案,而是:构建一个“大概率包含答案的候选集合”。
(具体名词解释在第三章)
二、检索方式的底层机制
为了让读者更容易理解,我们统一采用一个示例问题:“RAG技术如何减少幻觉?”
下面对三种检索方式从“底层机制→具象例子→失败原因→解决方案”做系统讲解。
2.1关键词检索(SparseRetrieval):基于词项的离散空间匹配
底层机制
关键词检索(如BM25)的数学本质是:将文本表示为高维稀疏向量,通过词项重合度与IDF进行评分。
它擅长处理:专有名词、技术概念、术语非常明确的领域(法律、API文档)
例如BM25的计算:
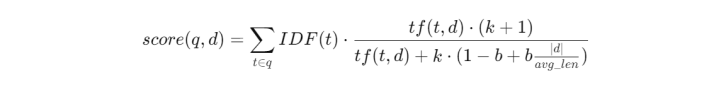
具象示例
用户问:“如何减少模型幻觉?”
文本A写:
“RAG通过知识库降低幻觉风险。”
→匹配成功文本B写:“提高事实性可减少错误内容。”
→因未出现“幻觉”二字→匹配失败
Sparse检索完全依赖词项重叠,因此表达方式变化会导致召回失败。
为什么会失败?(底层原因)
1.不理解同义词
2.不理解语义
3.用户表达方式与文档表达方式不一致
4.内容语言风格差异大
解决方案
1.QueryExpansion(同义词扩展)
2.Sparse+Dense混合检索3.构建领域术语词典
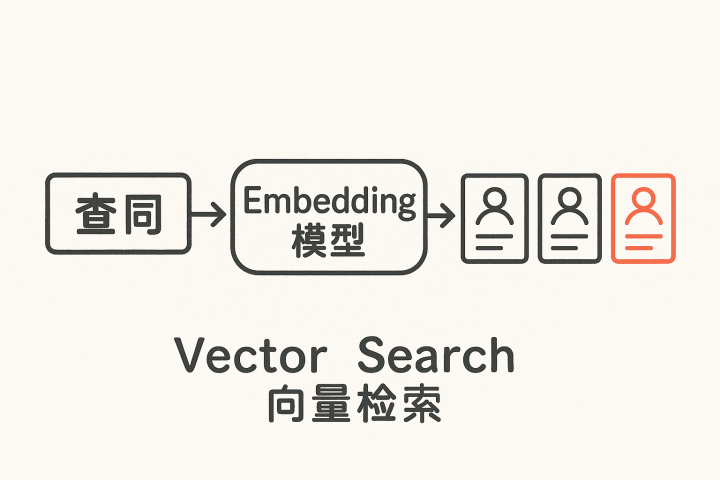
2.2向量检索(DenseRetrieval):embedding构建连续语义空间
底层机制
向量检索依赖embedding模型将文本压缩为向量:距离近=语义相似;距离远=语义不同。
embedding的核心是“语义压缩”,它不看字面,而是看价值密度最高的语义特征。
具象示例
“减少幻觉”embedding≈“减少错误内容”embedding→因为模型认为两者语义接近,因此能召回表达不同但语义相似的内容。
Dense会失败的根本原因(非常关键)
1.embedding会稀释关键信息:meanpooling会把所有词平均化,重要术语的权重被淹没
2.embedding的优化目标≠RAG的任务需求:它判断的是“语义是否相似”,不是“能否回答问题”
3.向量排序不稳定:相似度差距极小→Top-K排名可能随机波动,导致关键文本被漏召
解决方案
1.Cross-Encoderrerank
2.Multi-query扩展
3.更强embedding模型
4.语义分块(semanticchunking)
5.增大Top-K
2.3知识图谱检索(GraphRetrieval):基于关系结构的推理式检索
底层机制
知识图谱由实体、关系、属性构成可计算图结构,支持多跳推理、逻辑链路扩展、邻域检索。
具象示例
图谱中可能存在:RAG→引入知识库→增强事实性→减少幻觉
用户问“如何减少幻觉”,图谱检索可直接沿路径返回结果。
为什么图谱强但难落地?
1.NER(实体抽取)成本高
2.RE(关系抽取)难
3.实体消歧复杂
4.图谱维护成本高
5.对领域理解要求高
解决方案
1.图谱+Dense融合
2.构建局部图谱(LocalKG)
3.半自动关系抽取

三、检索工程指标:RAG系统成败的关键
RAG的绝大多数错误都不是模型造成的,而是检索阶段的问题。以下五大指标是系统能否稳定的核心。
3.1召回率Recall:找到了多少应该找到的?
为什么Recall会低?
1.embedding忽略关键术语
2.chunk切得太碎或切断语义
3.Top-K排序不稳定
4.用户/文档表达差异大
5.embedding模型表达能力弱
提升策略
1.Sparse+Dense融合
2.QueryExpansion
3.提高Top-K
4.语义分块
5.更强embedding模型
3.2准确率Precision:召回内容中真正有用的比例
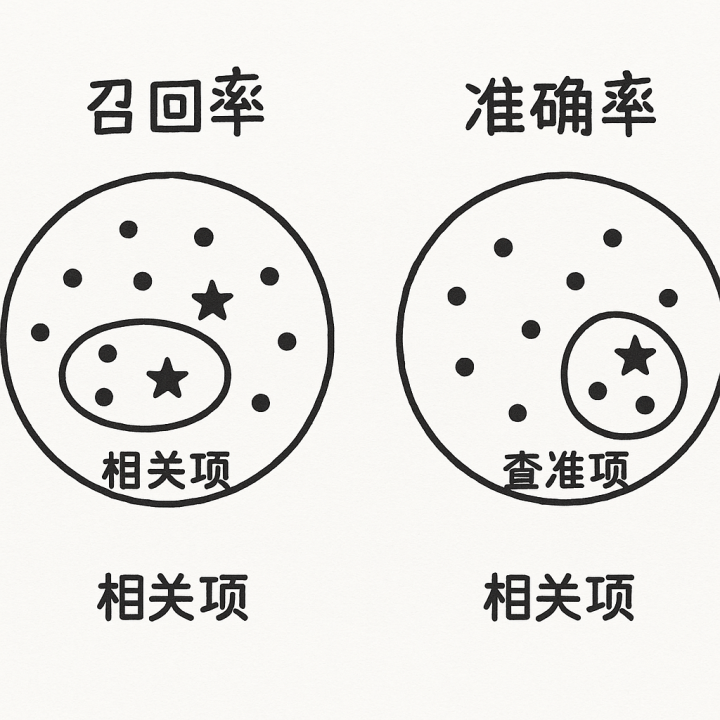
Dense常召回“看似相关但无用”的段落——典型语义偏差。
Why?
1.语义相似≠任务相关
2.Top-K过大噪声暴增
3.chunk过碎导致embedding歧义
提升策略
1.Cross-Encoder精排
2.控制Top-K
3.语义chunking
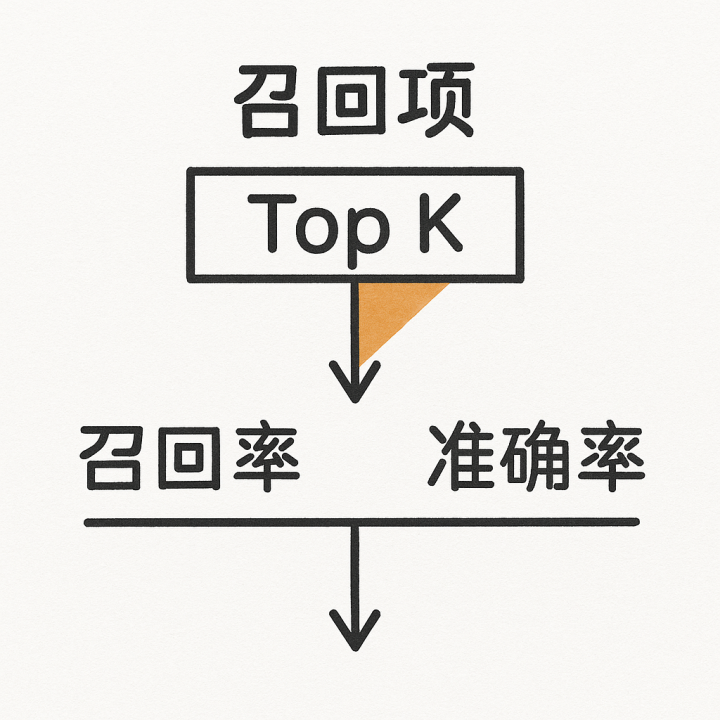
3.3Top-K:RAG可以调用多少内容?
K太小→Recall不够;K太大→Precision崩溃。最佳方法是:“相似度断层法(scoregap)”。
3.4检索延迟Latency:系统体验的底层硬性指标
延迟来源包括:embedding推理、ANN向量搜索、rerank、IO。
优化方式包括:GPUembedding、HNSW参数调优、缓存策略。
3.5Chunk策略:embedding的土壤决定检索效果上限
chunk切错=整个RAG崩盘。
最佳策略:语义分块(自动分段)、20–30%重叠、动态chunk、术语优先策略。
四、企业级检索架构:为什么最终都走向组合检索?
几乎所有成熟产品都采用:
Sparse(术语召回)+Dense(语义召回)+Graph(逻辑推理)→合并候选→Cross-Encoder精排→Top-K→增强(Augmentation)→生成(Generation)
这是一种“分工明确、互相补足”的架构。
五、全文总结
1.检索不是搜索,而是构建“模型可用的候选集合”。
2.召回率决定“能不能答对”,准确率决定“会不会答偏”。
3.Sparse/Dense/Graph构建的是完全不同的相似性空间。
4.Top-K是RAG效果最重要的旋钮。
5.Chunk质量决定embedding上限。
6.最终方案一定是多检索方式融合+精排。
RAG的成功,70%取决于检索,20%取决于增强,10%取决于模型。
(后续章节:增强/生成待补充……)
配资炒股首选提示:文章来自网络,不代表本站观点。




